Service mesh adoption doesn't have to be hard! Get tips on using GitOps to deploy Istio and manage your Kubernetes services.
Embracing Service Mesh Technology: Why Adoption Doesn't Have to Be Hard
In recent years, the concept of service mesh has gained significant traction in the world of software development and cloud-native architectures. Service mesh technology promises to simplify the management of microservices-based applications, enhance their resilience, and improve observability. Yet, despite its potential benefits, many organizations hesitate to adopt service mesh, fearing complexity and implementation challenges. However, it's time to debunk the myth that adopting service mesh technology has to be hard. In fact, with the right approach, it can be a smooth and rewarding journey.
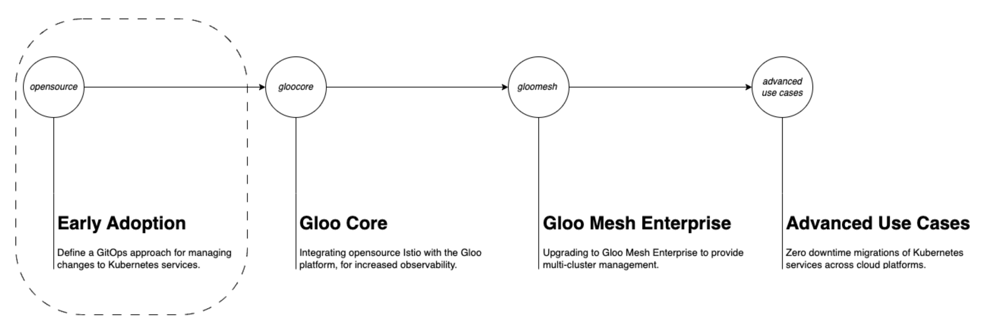
In this first post, we explore the early phases of adopting and overseeing Kubernetes services, particularly emphasizing the integration of Istio within an organization's infrastructure. This scenario centers on the organization's enthusiasm for adopting Istio but has yet to formalize its inclusion in the service catalog. Additionally, the organization may not have implemented GitOps practices for managing changes to Kubernetes services via continuous deployment tools. The focus will be on helping you understand how you can adopt a GitOps approach for proposing changes and use tools such as ArgoCD or FluxCD to manage the deployment and lifecycle of proposed changes.
Understanding the Fear
Before diving into the ease of adoption, it's essential to address the concerns that often deter organizations from embracing service mesh technology. Chief among these concerns are:
1. Complexity: Service mesh introduces additional layers of infrastructure and configuration, which can seem daunting to manage.
2. Learning Curve: Teams may feel overwhelmed by the need to learn new tools and concepts associated with service mesh.
3. Operational Overhead: Implementing and maintaining a service mesh will require time and resources, potentially impacting existing workflows. Who owns the service mesh?
Demystifying the Process
While these concerns are valid, they should not overshadow the benefits that service mesh can bring. Moreover, with the right approach, organizations can mitigate the challenges associated with adoption. Here's how:
1. Start Small: Start with a small, well-defined project rather than attempting to overhaul your entire architecture at once. Choose a non-critical service or a low-traffic environment to pilot the service mesh implementation. This allows teams to gain familiarity with the technology without risking major disruptions.
2. Invest in Training: Provide training and resources to your teams to help them understand the principles and best practices of service mesh. This might include workshops, online courses, or hands-on tutorials. By investing in education, you empower your teams to make informed decisions and effectively utilize service mesh capabilities.
3. Automation is Key: Leverage automation wherever possible to streamline the deployment and management of your service mesh infrastructure. Continuous Deployment tools such as ArgoCD and Flux can automate the deployment and lifecycle of service mesh components, reducing manual errors and accelerating the deployment process.
4. Monitor and Iterate: Continuous monitoring and feedback are essential for successful adoption. Monitor key metrics such as latency, error rates, and service availability to identify areas for improvement. Iterate your implementation based on real-world performance data and user feedback, gradually refining your service mesh configuration over time.
Early Adoption
Like most services that run on Kubernetes, Istio is backed by a large community and offers an official helm chart for deployment, but it is important to ensure that within your organization a consistent change management approach using GitOps is followed where proposed changes to any service including Istio are reviewed and deployed into your Kubernetes clusters using a consistent automated deployment pattern.
For example, many organizations will decide to have a dedicated Git repository for storing Helm charts and Kubernetes yaml files. This repository becomes the main hub for storing all current state configurations for all Kubernetes services and acts as the entry point for deploying the newly introduced changes to an organization's various Kubernetes clusters.
Let's take a look at how this concept is realized using GitOps.
.png?width=789&height=330&name=image%20(1).png)
The most important part of this flow is that the main branch is a protected branch where developers are forced to open pull requests for any changes being proposed. This simple configuration implicitly requires reviewers to approve changes that will eventually be deployed to a target Kubernetes cluster.
Let’s delve a little further down the rabbit hole and look at how the proposed changes get to a target Kubernetes cluster using an automated workflow. In this example, we will use GitHub Actions.
After the proposed changes are merged into the main branch, the above GitHub actions workflow will execute. The workflow will checkout the merged code, log in to the Kubernetes cluster, set up the Helm CLI on the actions runner, and then subsequently either install or upgrade only the helm releases that have new changes.
Most organizations have centralized repositories within GitHub for managing helm charts and the underlying values.yaml configuration. Often one service will be dependent on another service which will require a configuration change to the dependent helm chart values.yaml file.
To design for this, let's assume each helm chart configuration will reside in its folder within a GitHub repository. We could run a GitHub actions task to determine the folder paths that were modified since the last merged pull request into the main branch.
The Determine Changed Folders task can be added to create an output of only the modified directories under the helm-charts directory. The logic within the task returns all directories that have been modified since the previous pull request and creates a GitHub Output that can be used as input in any of the following tasksYou might have already caught the next problem, which is the possibility of more than one helm chart being modified for a single pull request. If we have two helm chart configurations that have committed changes and we execute a git diff on the repository, we will get a value of two directories.
You might have already caught the next problem, which is the possibility of more than one helm chart being modified for a single pull request. If we have two helm chart configurations that have committed changes and we execute a git diff on the repository, we will get a value of two directories.
We need to provide a process that iterates over the resulting output when the result has more than one path in the result.
One way GitHub Actions can be used to separate configuration changes into their helm deployments would be to use a separate GitHub Actions workflow for each service.
Under the triggers section of the workflows, the path for each chart is added with a wildcard to ensure this workflow executes when any file in the ./helm-charts/<service_name>/ directory is modified. directory is modified.
This method requires additional development work to onboard the new actions workflow file. A developer will need to create a new GitHub actions workflow file and modify the configurations of the workflow to match the new service being deployed. At the end of the day, it's just more stuff to manage and there is a better way to achieve the desired result with only a single GitHub actions workflow file.
We can create a second job for deploying the helm charts and define the job to use a matrix which will handle iterating over a GitHub Output without having to define any additional iterative logic. All we need to do is create a matrix job in GitHub Actions and create an output with the modified paths under the ./helm-charts sub-directory.
The above workflow will work, but there is a risk that not everyone will use the .yaml extension for the values file and could use the alternative extension of .yml. A change to the .yml extension would break this workflow. To solve this, we can create a VALUES_FILE bash variable and perform a search of the modified helm chart directory to retrieve all files with the string values in the name. The find command returns the relative path of a matching file. This variable will be added to the helm command in the Deploy Helm Charts task.
At this point, an automated process is in place to ensure only approved changes to official organization Kubernetes services are deployed to Kubernetes clusters. Organizations will often automate the deployment of Kubernetes services for non-production environments. Organizations will not deploy to production until all testing on non-production environments has been completed and the services are operating normally.
While this solution works well for deploying helm releases to Kubernetes clusters, the solution does not support other manifest packaging tools like Kustomize. Sure, we could just write another task in the workflow to handle deploying Kustomize directories using the kubectl apply -k <kustomization_directory> but we now need to add additional logic to isolate Kustomize managed directories from helm-managed directories.
This is where the introduction of new tooling can help provide a production-ready continuous deployment solution for all Kubernetes services developed within an organization.
ArgoCD and FluxCD are by far the most common tooling we see within organizations for managing the deployments of their Kubernetes services.
The tool's main value added as a replacement to the continuous deployment solution we developed is that all services are managed as individual deployments. If the source code contains a change for the istio service, ArgoCD and FluxCD take care of reconciliation automatically. The tools connect to the repository and all services are defined with the path to the configuration files and whether the source is Kustomize or a Helm resource.
Below is an example of how we could replace our GitHub Actions workflow with ArgoCD Applications for each Kubernetes service using the ArgoCD Application custom resource definition. This step assumes you have ArgoCD running somewhere with a repository connected using one of the supported authentication methods.
Centralized Folder Structure
Within a GitHub repository named helm-charts, all company-managed helm charts reside here and are the source of truth for continuous deployment tools when managing the lifecycle of a Kubernetes service that is configured using a Helm chart.
Below is an example of two helm charts that is managed by a company named istio and prometheus.
ArgoCD Applications Files
Within the same repository, an apps folder contains all the application deployment manifests for the helm-charts directory. Because tools like ArgoCD and FluxCD have Custom Resource Definitions (CRDs), we can configure the applications within these tools using the same yaml syntax as any other Kubernetes manifests. This means we can package all the application deployment manifests into a single Helm chart. In the example below, we have a helm chart that registers all the applications with ArgoCD. Once registered, ArgoCD will deploy the individual application helm charts while also managing the ongoing lifecycle of the applications going forward.
The values.yaml file contains important information regarding the target cluster URL and the source code location where the helm-charts repository is located.
The templates directory holds all the Application manifests with deployment information on how ArgoCD will manage the application. This manifest is what registers the application to ArgoCD for lifecycle management when new changes are made against the helm-charts repository.
templates/helm-istio.yaml
templates/helm.prometheus.yaml
Aside from providing lifecycle management and continuous deployment for Kubernetes services, ArgoCD provides a full user interface with a visual breakdown of the applications by the individual service. Each service shows the health status and current revision.
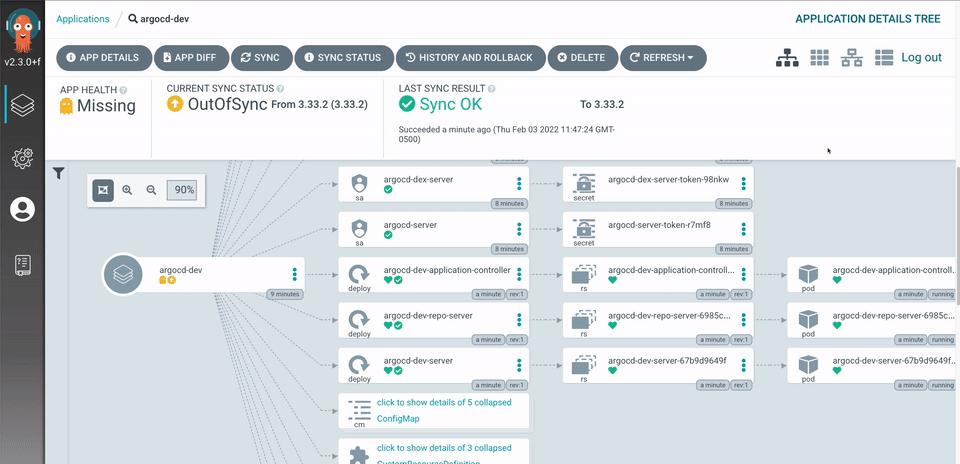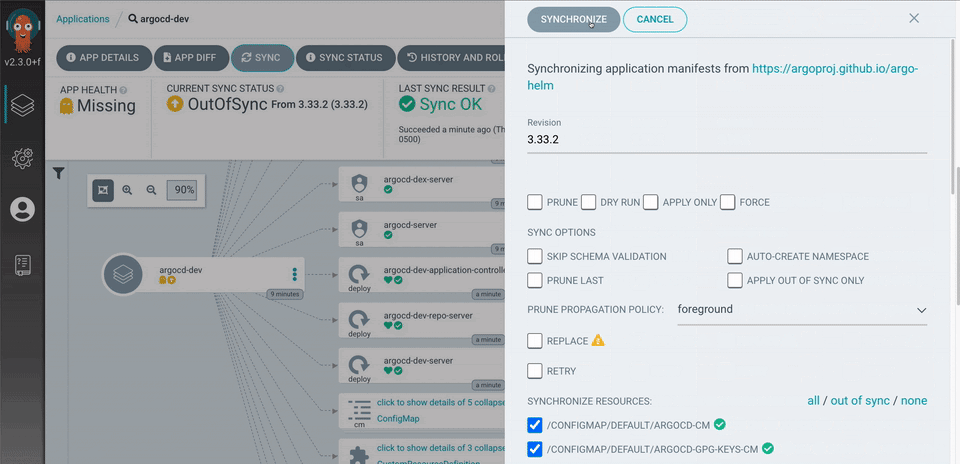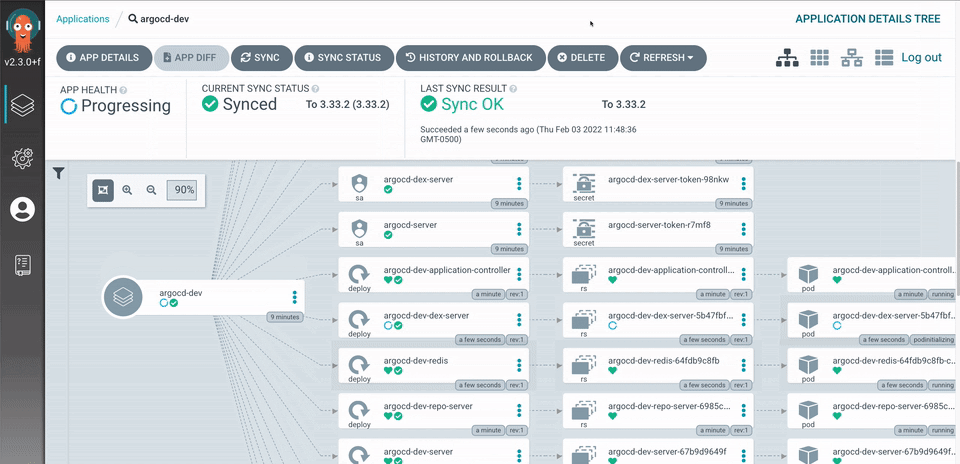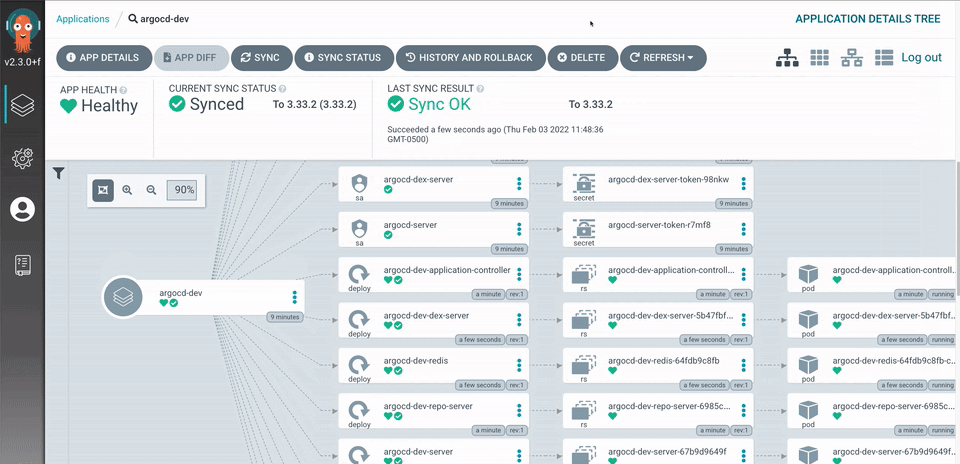
- Imagine Helm and Kustomize as a package manager for Kubernetes yaml files. It creates a single versioned deployable object with an override configuration.
- Imagine ArgoCD and FluxCD as a wrapper around the packaged Helm or Kustomize object where anything related to the lifecycle of the application on the target cluster is handled and deployed by Argo and Flux.
Below is a diagram that illustrates the relationship between a Kubernetes package manager and a continuous deployment toolset.
.png?width=3135&height=1310&name=image%20(1).png)
Conclusion
Service mesh technology holds tremendous potential for organizations looking to modernize their application architectures and embrace cloud-native principles. While the prospect of adoption may seem daunting, it doesn't have to be hard. By taking a systematic approach, investing in training, and leveraging automation, organizations can successfully integrate Kubernetes services into their infrastructure, unlocking a wealth of benefits in terms of observability, security, resilience, and operational efficiency. So don't let fear hold you back – embrace new technologies and pave the way for a more resilient and scalable future.
While leveraging automation tools to get Istio deployed into a development environment might be quick and easy, Istio production-ready involves tuning various configurations to ensure the service mesh is secure, resilient and performs well under the expected load. These configurations touch upon aspects such as security policies, traffic management, observability, and resource allocation. In the next blog post in the series, we will look at how the Gloo platform by solo.io seamlessly integrates into an existing open-source implementation of istio to simplify the management and observability of the Istio service mesh.



.png?width=380&height=170&name=Untitled%20(3).png)